







Hash Table and Function

Published by
sanya sanya
What is hash table?
Hash table is a data structure that maps keys to values using hash functions. Hash holds the data in an array in an associated fashion, giving each data value a distinct index. It stores an array of pointers which point to node*.
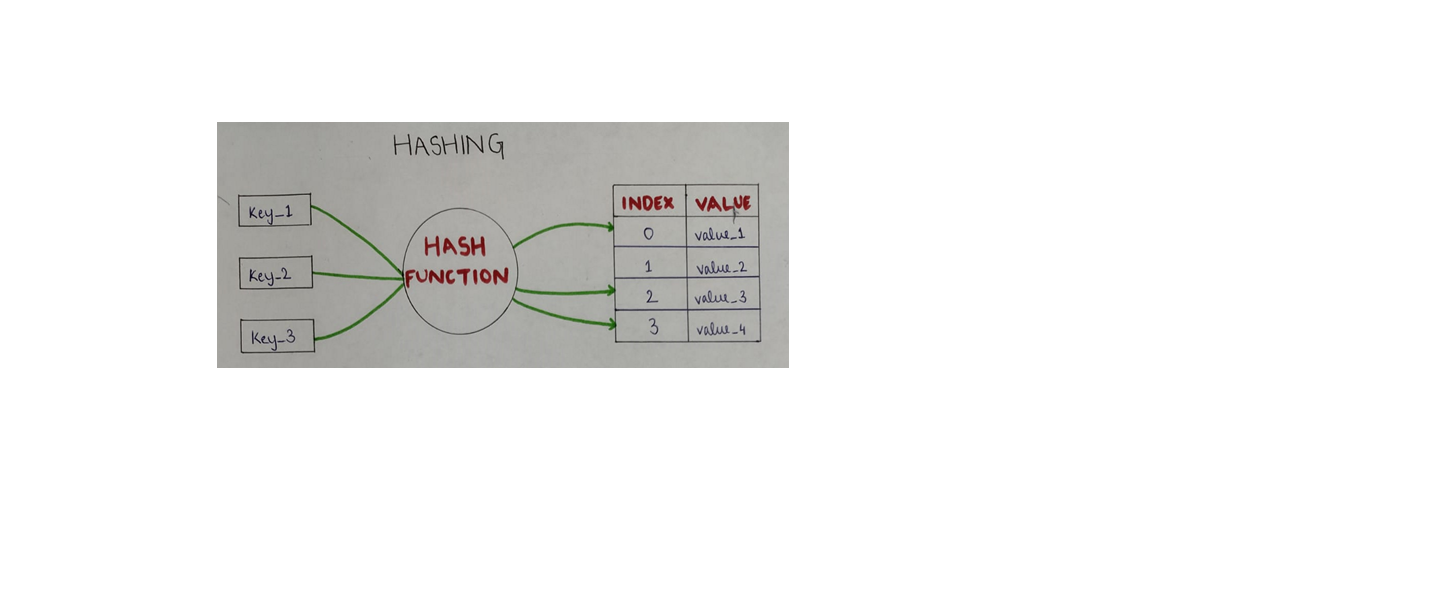
What is hash function?
Hash functions are special functions that convert a received input key to an index of array called hash table. This index is known as hash code or hash value.
There are various types of hash functions that are mathematical functions which generate a hash code or index. This index of hash table allows us to map key to its values efficiently. Some of these functions include:
- Division Method: This is the easiest hash function where in the key is divided by a number ‘N’, preferably a prime number as it further reduces collision, and using the remainder as hash value.
Hash Code= key%N
Example: Let N=29, key= 780
Hash Code= 780%29
=26
- Multiplication Method: In this method, key is multiplied by a fractional constant, fractional part is extracted and multiplied by the size of the hash table. The integer part of result is taken as the hash code.
Hash Code = floor(table_size * ((key * A) % 1))
Here, ‘A’ is a constant value between 0 and 1.
Example: Let table_size=7, A=0.6180339887 (Golden ratio) as the
constant, key = 23
Hash Code= floor(7 * (( 23 * 0.6180339887) % 1))
= 2
- Mid Square Method: In this method, the key is squared and a portion of the squared value is used as hash value.
Hash code = h(k*k)
Example: Let key=42
Hash code= 42*42 = 1764
From 1764, 76 can be extracted and used as hash value.
- Digit Folding Method: This method involves dividing a key into smaller parts, folding, or combining those parts, and use the result as the hash code. The parts can be combined in numerous ways.
Hash Code = k1+ k2 + k3
where k1, k2, k3 are parts of key
Example: Let key=123456789
k1=12, k2=34, k3=56, k4=78, k5=9
Hash Code= k1 XOR k2 XOR k3 XOR k4 XOR k5
= 12 XOR 34 XOR 56 XOR 78 XOR 9
= 11
How to choose hash function?
Deciding which hash function to choose depends on several factors, including the specific requirements and constraints of your application or problem domain. Here are some ways which can help in deciding which hash function to choose:
1. Understand the Requirements: Consider factors such as the size of the data set, expected number of elements, desired retrieval and insertion performance, memory constraints, and any security considerations.
2. Evaluate Hashing Techniques: Understand the properties, advantages and limitations of various types of hashing techniques such as division method, multiplication method etc. Consider which techniques are best suited for your specific requirements.
3. Analyse the Data: Examine the characteristics of the data you'll be hashing. Consider the distribution of the data, its size, and any specific patterns or features. Some hash functions may perform better for certain data distributions or types.
4. Consider Existing Libraries or Frameworks: Hash functions provided by standard libraries and frameworks are well- tested and optimized. These provide a reliable solution to general hashing needs.
Properties of a good hash function: A hash function that generates a unique index for every key is known as a perfect hash function. However, this is unachievable. Hence, we look for a good hash function that satisfies the following properties.
- Uniform Distribution: A good hash function provides hash codes across the entire range of possible inputs. This means that each input should have an equal chance of producing any possible hash code. Uniform distribution helps minimize collision and ensures data is evenly distributed in the hash table.
- Efficiency: Hash function should be computationally efficient and provide fast hashing performance. This property is particularly important when dealing with large data sets.
- Collision Resistance: Low collision probability is the most important characteristic of a good hash function.
- Low Load Factor: Load factor is the number in the table divided by the size of the table. A low load factor means that number of elements in hash table is relatively small compared to the total capacity of the hash table.
Load Factor
- What is a load factor?
The load factor is a measure of how full the hash table is. It is calculated as the ratio of the number of elements stored in the hash table to the total number of slots or buckets in the hash table.
The load factor provides insights into the occupancy of the hash table and helps determine if resizing or rehashing is necessary. A high load factor indicates that the hash table is approaching its capacity and may result in increased collisions and degraded performance. On the other hand, a low load factor suggests that there is ample space available in the hash table, potentially leading to better performance with reduced collisions.
- How to find load factor?
The load factor (LF) is determined using the following formula:
LF = Number of elements in the hash table / Size the hash table
Here is an example to illustrate the calculation of the load factor:
Suppose you have a hash table with a total of 100 slots, and it currently contains 75 elements. The load factor would be:
LF = 75 / 100 = 0.75
In this case, the load factor is 0.75, which means the hash table is 75% full.
Library
WEB DEVELOPMENT
FAANG QUESTIONS