







Collision Resolution Techniques

Published by
sanya sanya
Collision resolution techniques are used in hash tables to handle situations where two different keys map to the same hash code. When a collision occurs, these techniques help resolve the collision and find an appropriate location for storing the colliding keys.
- Separate Chaining:
- In separate chaining technique, each bucket in hash table is associated with a linked list or some other data structure that can store multiple elements.
- When a collision occurs, the colliding elements are added to the linked list associated with that bucket.
- The key and its corresponding value are stored as a node in list.

- Open Addressing
- In open addressing, when a collision occurs, the hash table’s slots themselves are used to store the colliding elements. If a slot is already occupied, the algorithm probes or searches for the next available slot in a predetermined manner.
- The probing technique determines the sequence of slots to be checked when searching for an empty slot. Common probing techniques are discussed below:
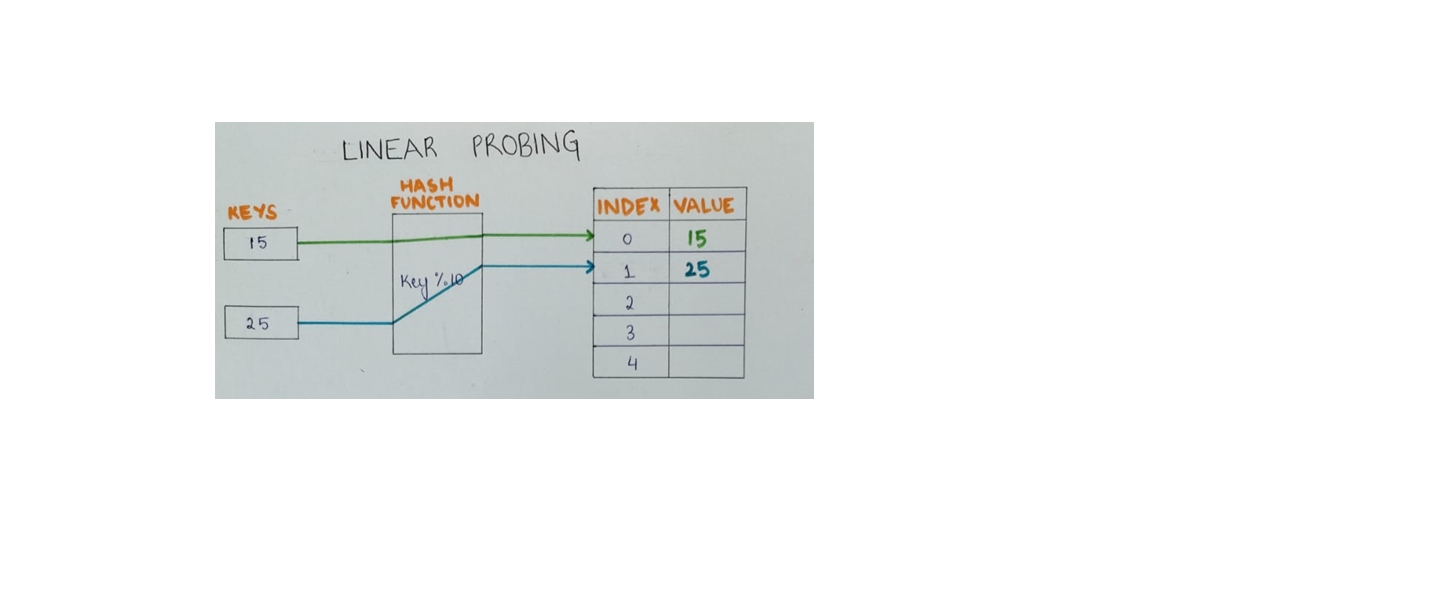
- Linear Probing:
- In linear probing, if a collision occurs at a specific slot, the algorithm sequentially searches for the next available (empty) slot by incrementing the index one by one until it finds an empty slot.
- The probing sequence is defined by the linear function:
‘hash(key) + i’
where ‘hash(key)’ is the original hash value and ‘I’ is the probe number.
- Quadratic Probing:
- Quadratic probing uses a quadratic function to determine the probing sequence. The formula is:
‘hash(key) + (c1 * i ) + (c2 * i^2)’
where ‘hash(key)’ is the original hash value, ‘i’ is the probe number, and ‘c1’ and ‘c2’ are constants.
- Quadratic probing attempts to reduce primary clustering (consecutive clusters of occupied slots) that can occur with linear probing.
- Double Hashing:
- Double hashing involves using a secondary hash function to determine the step size for each probe. The formula is:
‘hash(key) + i * hash2(key)’
where ‘hash(key)’ is the original hash value, ‘I’ is the probe number, and ‘hash2(key)’ is the secondary hash function.
- Double hashing aims to avoid clustering and produce a more evenly distributed probing sequence.
Library
WEB DEVELOPMENT
FAANG QUESTIONS